Key results
Table of Contents
Key result 1: Feasibility study
The key result “Feasibility study” elaborates a concept for a digital neuromorphic hardware platform, supporting fast, deterministic, and reproducible simulations of biologically plausible, spiking neural networks with realistic connection density.
During the first phase of the project, the following major challenges have been identified: (1) “Bringing the spikes to the computational units” with ultra-low latency communications; (2) accessing the synapse parameters from high-capacity memory units with ultra-low latency; (3) implementation of future, yet unknown complicated synaptic plasticity rules, possibly combined with compartmental dendrite models; and (4) coping with only vague requirement specifications for numerical accuracy and precision of future network models.
To overcome these challenges, a proposal for a radically new architecture is elaborated: (1) Based on a system model, comprising all considered neuroscience test cases in a formalized way, a promising new network topology, consisting of overlaid meshes is derived. In light of this and other possible topologies, a set of algorithms for deadlock handling, network synchronization and routing is designed. As the stringent communication-latency constraints do enforce very short physical interconnect distances, a 2.5-D integration on wafer-scale silicon interposers is proposed, transforming the initial latency requirements into a very-high integration-density requirement. Ultimately, those wafers could be stacked in the third dimension, transforming the integration-density requirement into an ultra-low energy-dissipation requirement. (2) The use of connectivity units, supporting procedural network generation, can significantly reduce the memory-capacity requirements. Additionally, very-large on-chip memories based on embedded DRAM technology are proposed and appear to become a must in highly accelerated systems. (3) Highly complex plasticity models can be efficiently and flexibly implemented on programmable RISC-V Floating-Point cores. (4) Number crunching, massively parallel, and highly efficient arithmetic blocks, incorporating custom macros for atomic floating-point operations are proposed for the ODE solver blocks. Plain-vanilla as well as more sophisticated solver methods with adjustable order and optional sub-stepping can be implemented on a weakly programmable multiplexed-ASIC structure. Quantitative, parameterized algebraic cost models for latency, silicon area and energy dissipation are elaborated for the whole accelerator architecture and its components, assuming a fabrication in a moderately new but affordable 22-nm CMOS technology. Based on a “specification-parameter corridor” derived from a set of neuroscience test cases and these cost models and the use of diverse simulation tools, an extensive design-space exploration is conducted.
Key result 2: Brain connectivity concepts
The key result “Brain connectivity concepts” constitutes a literature review of commonly used network structures and their description in computational neuroscience. It shows that these descriptions are highly diverse and often incomplete due to missing standards.
We first review neuronal network models published by the computational neuroscience community in online repositories and investigate the corresponding connectivity structures and their descriptions in both manuscript and code. The review comprises the connectivity of networks with diverse levels of neuroanatomical detail and exposes how connectivity is abstracted in existing description languages and simulator interfaces (see Figure 1). We find that a substantial proportion of the published descriptions of connectivity is ambiguous. Based on this review, we derive a set of connectivity concepts for deterministically and probabilistically connected networks and also address networks embedded in metric space. Beside these mathematical and textual guidelines, we propose a unified graphical notation for network diagrams to facilitate an intuitive understanding of network properties. Examples of representative network models demonstrate the practical use of the ideas.The aim of this work is to establish a common language that ensures that two neuroscientists using the same term or symbol mean the same thing. With an increased degree of consistency, we not only want to contribute to a higher reproducibility of studies, but also enable more complex and at the same time manageable models.
Corresponding publication: Senk et al., 2022.
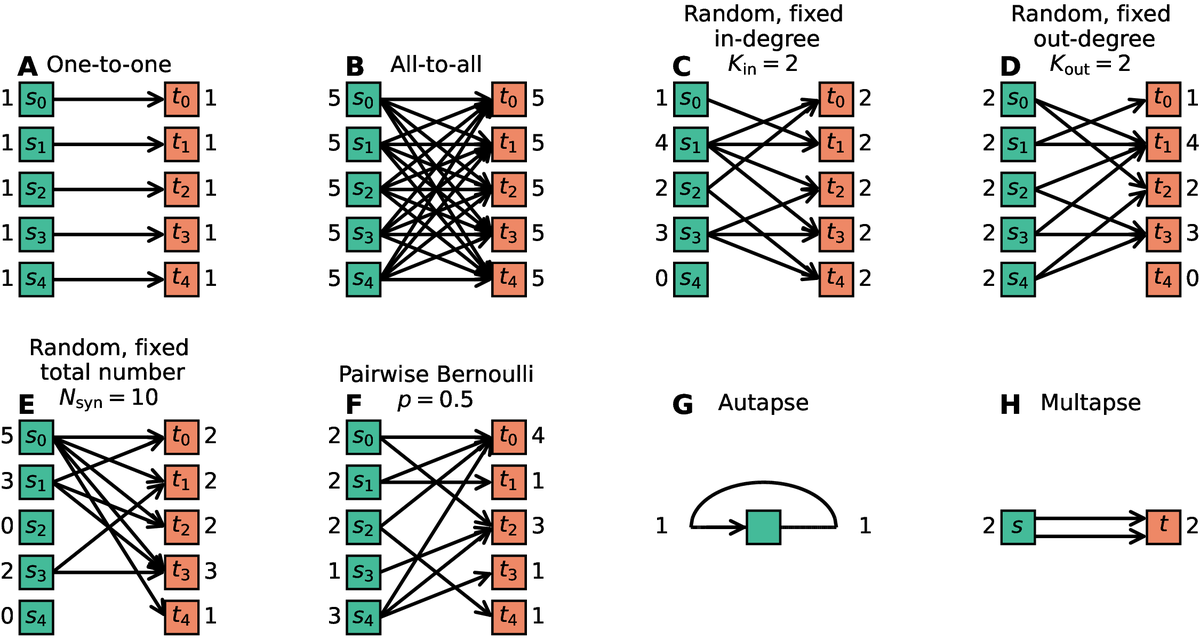
Figure 1 Connectivity patterns reflecting the most common rules. copyright: Senk et al. 2022, Figure 7, CCBY.
Key result 3: Test cases
Neuromorphic hardware development needs to be accompanied by a co-design process ensuring that the developed system satisfies the needs of the customers and incorporates state-of-the-art neuroscientific insights. To this end, one goal of this project is to set up a representative ensemble of “test cases” with neuronal network models from the Neuroscience literature.
The set of test cases developed comprises models describing biological neuronal networks at a variety of spatial scales, with diverse connectivity structures and a broad range of neuron, synapse and plasticity dynamics. The model documentations consist of an overview of each model including its scientific purpose and model validation metrics, and a detailed mathematical description of the underlying network structure, dynamics, and parameters in tabular form. Reference implementations are provided in NEST (Gewaltig & Diesmann, 2007), and accompanied by scripts demonstrating usage and by reference data for comparison with alternative implementations (see Figure 2).
The need for a set of diverse test cases in Neuromorphic Computing is illustrated in a number of other projects carried out in the context of ACA. The spiking temporal-memory model of Bouhadjar et al. (2022), for example, has been used to investigate the role of certain device characteristics for the network performance when replacing synapses by memristive elements (Bouhadjar et al., 2022b). The cortical microcircuit model of Potjans & Diesmann (2014) has been employed to study the effect of quantized synaptic weights (Dasbach et al., 2021), and to demonstrate the potential of FPGA-based computing architectures (Heittmann et al., 2022). A plastic version of the model proposed by Brunel (2000) has been used to benchmark simulation code (Jordan et al., 2018) and for testing benchmarking workflows (Albers et al., 2022).
Future work work will develop concepts and tools for a continuous integration of new models, a simplified handling of the test cases by the user, an automated extraction of hardware requirements, as well as an automated generation of human-readable model documentation. Moreover, it will implement methods enabling an exact scaling of recurrent neuronal networks.
The documented set of test cases is available on ACA GitLab.

Figure 2 Example of a test case (Vogels & Abbott, 2005) comprising a model overview (top left), a detailed tabular description (bottom right), and a reference implementation (bottom left). The panel in the top right corner depicts the contents of this test case. copyright: Tom Tetzlaff, Jülich Research Centre
Key result 4: Benchmarking Framework
Benchmarking experiments in High-Performance Computing (HPC) are often complex and therefore difficult to organize, compare, and reproduce. The key result “Benchmarking framework” proposes a generic benchmarking workflow that decomposes the endeavor into manageable modules.
We characterize the challenging complexity of benchmarking experiments according to multiple dimensions: hardware and software configuration, simulators, models and parameters, and the communication between researchers. Subsequently, we define a generic workflow that decomposes the benchmarking endeavor into unique segments consisting of separate modules (see Figure 3). As a reference implementation for the conceptual workflow, we introduce beNNch, an open-source software framework for the configuration, execution, and analysis of benchmarks for neuronal network simulations. The framework records benchmarking data and metadata in a unified way to foster reproducibility. For illustration, we measure the performance of various versions of the NEST simulator across network models with different levels of complexity on a contemporary HPC system, demonstrating how performance bottlenecks can be identified, ultimately guiding the development toward more efficient simulation technology.
Corresponding publication: Albers et al., 2022
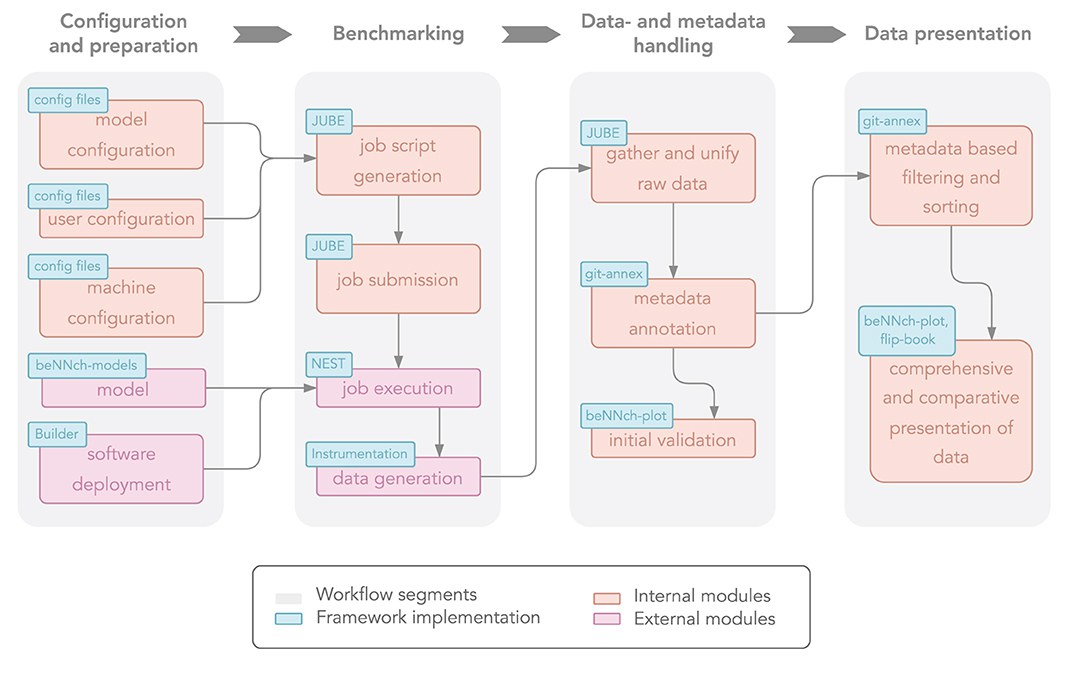
Figure 3 Conceptual overview of the proposed benchmarking workflow. Light gray boxes divide the workflow into four distinct segments, each consisting of multiple modules. Internal modules are shown in orange and external ones in pink. Blue boxes indicate their respective realization in our reference implementation. copyright: Albers et al. 2022, Figure 2, CCBY.
Key result 5: Multi area model on SpiNNaker
The work on the key result “Multi area model on SpiNNaker” aimed at an implementation of a large scale model of the brain circuitry encompassing several cortical areas on the neuromorphic hardware system SpiNNaker. As an important milestone, a cortical microcircuit model of a single area has been made to run in real-time through modification of the software to have multiple SpiNNaker cores receive spikes from different incoming populations.
Although it has not yet been possible to execute the model in real-time, the effort has led to several improvements in the SpiNNaker mapping software, including improvements in placement and routing of the network on the hardware. These both make it possible to load the network at all through the generation of more compact routing tables (to the extent that in the cortical microcircuit model, compression was not necessary at all), and in the speed of execution of the mapping, which is now possible in less than 2 hours. This makes it possible to test various other ideas in execution to run the network. So far, these runs have not been successful due to technical issues, including potentially the issue of Single Event Upsets due to the size of the area of silicon in use when this network is executed. Mapping the full model to the hardware requires over 500 SpiNNaker boards. Single Event Upsets occur at a rate of 2-3 per hour on the whole machine, so the chance of one such event occurring in simulation is non-zero at this scale. Work is ongoing beyond the end of the project to address these issues.
Key result 6: Downscaled Microcircuit model on BrainScaleS
The key result “Downscaled microcircuit model on BrainScaleS” adapts the cortical-microcircuit model to the BrainScaleS (BSS) neuromorphic hardware systems with a focus on preserving the asynchronous irregular firing behavior.
The efforts to port the cortical microcircuit model to the BrainScaleS hardware systems were twofold. On the one hand the model is adapted to fit the constraints of the hardware system. In a NEST simulation, it is downscaled to 10% of the neuron number and in-degree size, the external Poisson input is replaced by a current source, the model is changed to conductance-based synapses, and parameter variations are introduced. This preserves the asynchronous irregular firing in the simulation. On the other hand, the hardware usage is optimized to fit the requirements of the model. The stability of the system is increased, and close monitoring is implemented. Digital tests were developed to minimize the effects of malfunctioning components. The calibration of the hardware is extended and customized for the model. The number of lost synapses is reduced by improvements to the place and route algorithm and on-chip communication is made more robust. With the optimized hardware setup, the adapted model is successfully emulated on the hardware, showing the expected asynchronous irregular firing behavior (see Figure 4). Furthermore, an improved analog readout module is commissioned that allows for the simultaneous recording of 84 membrane traces. In addition, first steps towards large-scale experiments with the next-generation neuromorphic hardware are achieved through the development of a printed circuit that connects 46 HICANN-X chips.
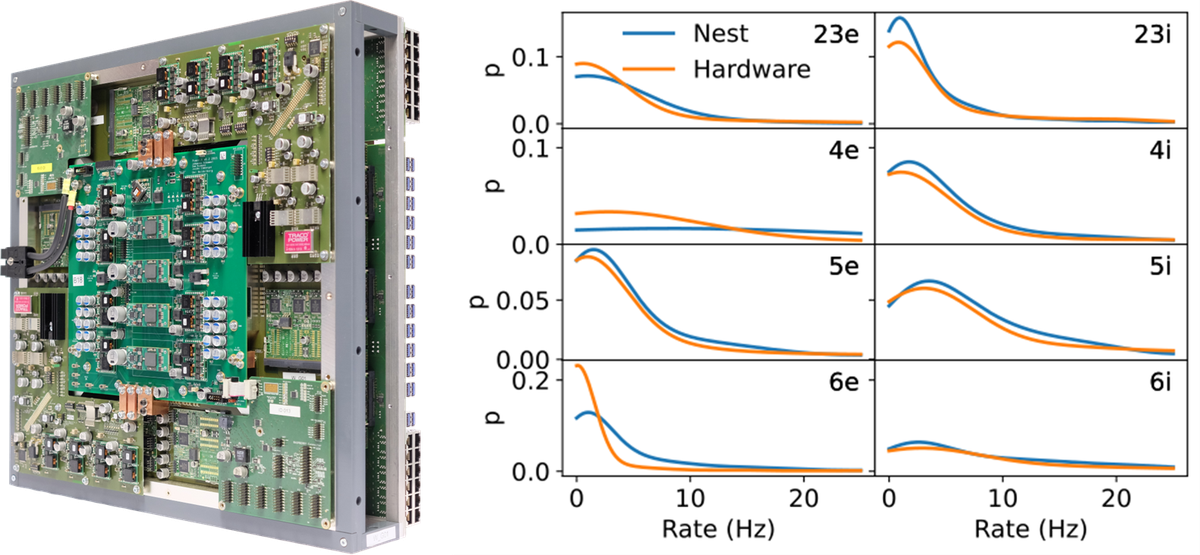
Figure 4; Left: BrainScaleS-1: A wafer-scale neuromorphic hardware system. Right: Firing rate probability of the adapted NEST simulation and the hardware emulation on BrainScaleS-1 of the downscaled cortical-microcircuit model. copyright: Heidelberg University (CC BY-ND 4.0)
Additional references
- Brunel, N. (2000). Dynamics of sparsely connected networks of excitatory and inhibitory spiking neurons. Journal of Computational Neuroscience, 8(3), 183-208.
- Bouhadjar, Y., Siegel, S., Tetzlaff, T., Diesmann, M., Waser, R., & Wouters, D. J. (2022b). Sequence learning in a spiking neuronal network with memristive synapses. arXiv preprint arXiv:2211.16592.
- Gewaltig, M. O., & Diesmann, M. (2007). NEST (NEural Simulation Tool). Scholarpedia, 2(4), 1430.
- Jordan, J., Ippen, T., Helias, M., Kitayama, I., Sato, M., Igarashi, J., ... & Kunkel, S. (2018). Extremely scalable spiking neuronal network simulation code: from laptops to exascale computers. Frontiers in Neuroinformatics, 2.
- Potjans, T. C., & Diesmann, M. (2014). The cell-type specific cortical microcircuit: relating structure and activity in a full-scale spiking network model. Cerebral Cortex, 24(3), 785-806.
- Vogels, T. P., & Abbott, L. F. (2005). Signal propagation and logic gating in networks of integrate-and-fire neurons. Journal of Neuroscience, 25(46), 10786-10795.