Learning to Learn (L2L) on HPC
Summary
"Given a family of tasks, training experience for each of these tasks and a family of performance measures, an algorithm is said to learn to learn if its performance at each task improves with experience and with the number of tasks." (S. Thrun and L. Pratt, 1998)
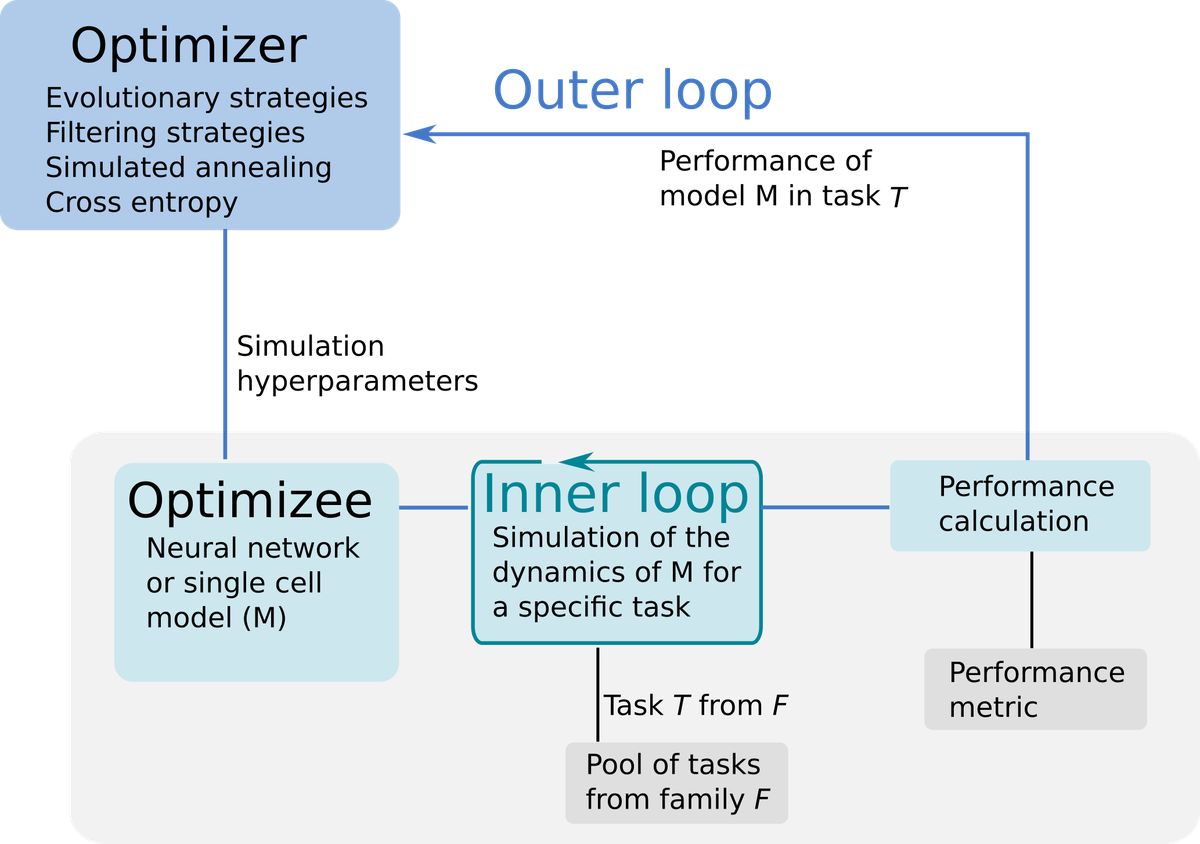
Learning to learn (L2L) is a specific method to improve learning performance. In a normal learning regime, a program is trained against samples from a single task. A well-defined performance measure is required in order to improve its performance against new samples from that same task. L2L generalizes learning using a two-loop structure (see Figure). In the inner loop the program adapts to learn a specific task. In the outer loop the program’s general performance is improved by training against samples from a new task from a family of tasks. This is achieved by optimizing the learning of hyperparameters (such as a set of synaptic plasticity values) across the family of tasks in the outer loop as the whole system evolves over training runs.
Project description
Exploring the consequences of parameter changes on the observables in simulation or analytical software is a common practice and general challenge in all computational sciences, as a generalization of the experimental method to numerical analysis. In close collaboration with different collaborators in and outside of the Human Brain Project, we are further developing the [L2L framework](https://github.com/Meta-optimization/L2L), which enables large scale parameter space explorations and optimization of simulations on HPC systems.
By extending L2L with the UNICORE and JUBE frameworks developed at the JSC, we provide a flexible platform for parameter exploration using well known optimization algorithms.
Our contribution
We implement and integrate machine learning algorithms within the L2L framework. The framework is able to use the batch systems of high-performance computers (e.g. SLURM), especially on the supercomputers of the JSC. We are also benchmarking the performance of long running optimization sessions.
Specific examples
* Structural Plasticity in NEST
* EnKF-NN & non gradient based methods
* Connectivity in the cortical microcircuit (COMET project in collaboration with INM-6)
* Multi-agent simulations with NEST and NetLogo
* Single cell optimizations with Arbor, NEURON and Eden
* Whole brain simulations using The Virtual Brain
Our collaboration partners
This project is being conducted in collaboration with the research group of Prof. Wolfgang Maass at Graz University of Technology, Dr. Anand Subramoney from Ruhr-Universität Bochum, the Arbor development group at JSC and ETH Zürich, Dr. Mario Negrello at Erasmus MC in Rotterdam, Prof. Sacha van Albada from INM-6 and Dr. Oleksandr Popovych from INM-7 at Forschungszentrum Jülich, Prof. Thomas Nowotny from the University of Sussex, and other partners in the Human Brain Project.
References
[1] S. Thrun, L. Pratt (eds) Learning to Learn. Springer, Boston, MA, 1998
[2] S. Diaz-Pier, C. Nowke, and A. Peyser. Efficiently navigating through structural connectivity parameter spaces for multiscale whole brain simulations. In 1st Human Brain Project Student Conference, page 86, 8-10 Feb. 2017.
[3] [OCNS poster](https://ocns.memberclicks.net/assets/CNS_Meetings/CNS2019/Posters/P119.pdf)